

Internet Archiveで消えてしまったWebサイトを確認する。
最近あるWebサイトを確認しようとした際、Webサイトが閉鎖しており見れなくなってしまったことがありました。
更新されているかの確認というよりは、過去に掲載されていた内容を再度確認したいという理由で訪れたのですが、サーバー管理者側で閉鎖してコンテンツを削除してしまうと情報を確認することができません。
ですが、Internet Archiveを使用することで閉鎖されたサイトの情報を確認することができます。
今回はInternet Archiveを使用して、閉鎖されたサイトを確認してみようと思います。
他に消えてしまったWebサイトをまた見たいという方がいれば、参考にしていただければと思います。
Internet Archiveとは何か。
Internet Archiveはwikiの情報では以下の様になっています。
インターネットアーカイブ (Internet Archive) は、WWW・マルチメディア資料のアーカイブ閲覧サービスとして有名なウェイバックマシン (Wayback Machine)を運営している団体である。
Wikipedia「インターネットアーカイブ」から引用
本部はカリフォルニア州サンフランシスコのリッチモンド地区に置かれている。
電子資料保存の支援と、人類の知識と遺産を保存してそのコレクションを公開することを目的にしている団体のようです。
人類の知識と遺産とは少々大げさですが、インターネットを機械的に周回して情報を収集して保管しているためアメリカの団体ですが、日本のWebサイトの情報も収集して保管されています。
恥ずかしい黒歴史をブログやWebサイトで公開していた人は、その情報も人類の知識と遺産としてアーカイブされていると思いますので、確認して悶絶してみてはいかがでしょうか。
Internet Archiveの使用方法
Internet Archiveの使用方法は、まずInternet Archiveのページを開きます。
開くと以下の画面となりますので、Searchの部分に消えてしまったWebサイトのURLを入力してGoを押すと、アーカイブされたWebページが表示されます。
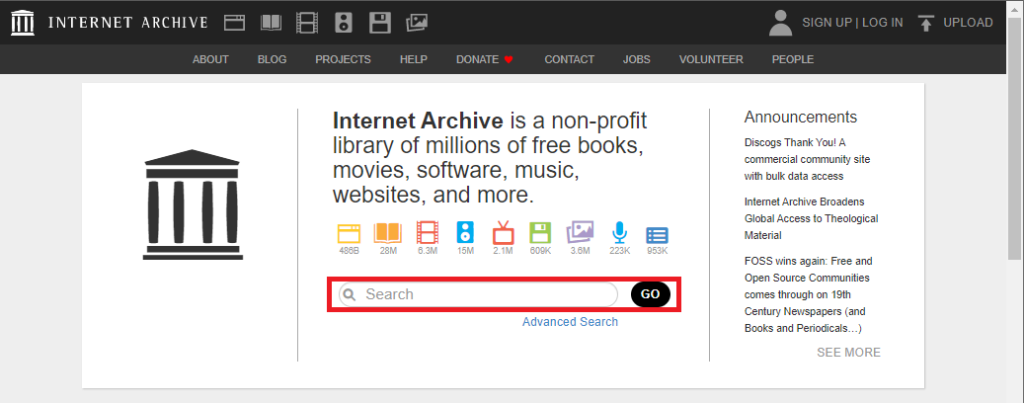
入力の際、検索するデータの種別を選択する画面が表示されますが、消えたWebサイトを確認したい場合は、一番下のSearch archived web sitesを選択します。
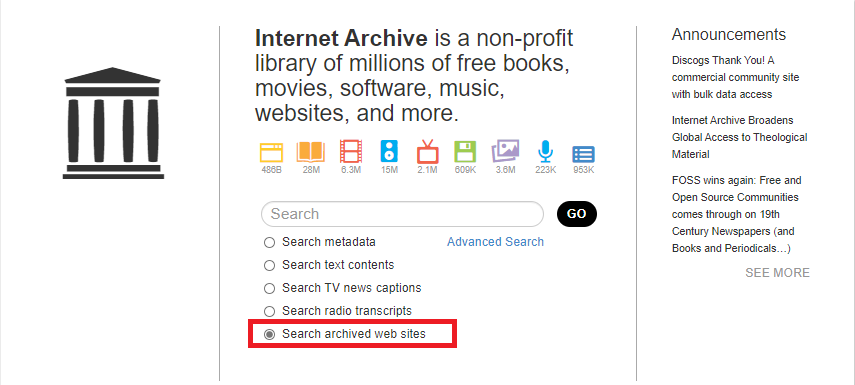
その他の検索項目をざっと説明すると、Search metadataは内容のとおりメタデータレコード内のみ検索します。
通常、タイトル、公開日、説明、件名、アップロードした個人、組織の情報が含まれています。
Serach text contentsはアーカイブされている全てのテキストデータを検索します。
メタデータや、ビデオのキャプションや、画像内のテキストについては検索されません。
Search TV news captionsとSearch radio transcriptsはテレビニュースやラジオのコンテンツを検索します。
昔のサイトを確認したい場合は、大体お気に入りに追加している場合が殆どであると思いますので、お気に入りの編集画面からサイトのURLを確認することが可能です。
検索例で検索してみる。
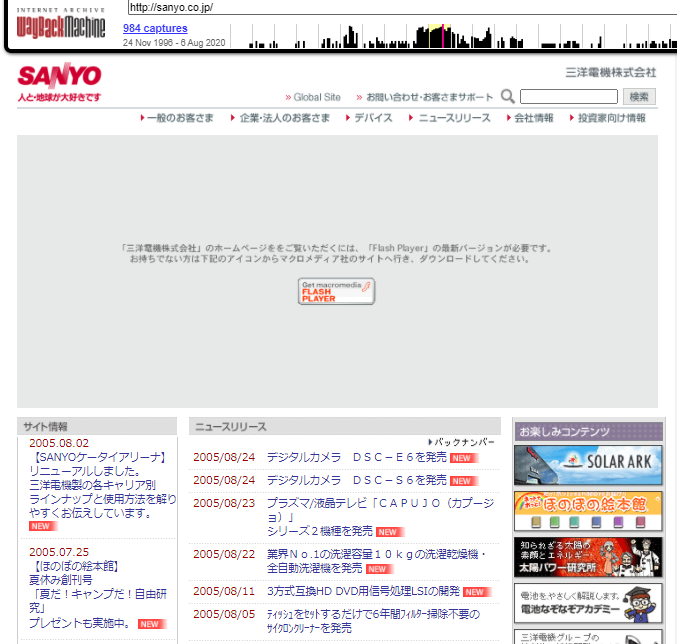
ここでは例として三洋電機の過去のWebサイトを確認してみようと思います。
三洋電機は現在はPanasonicに買収されているため三洋電機のWebサイトはありません。
検索画面で三洋電機のURLを入力すると以下の様に表示されます。
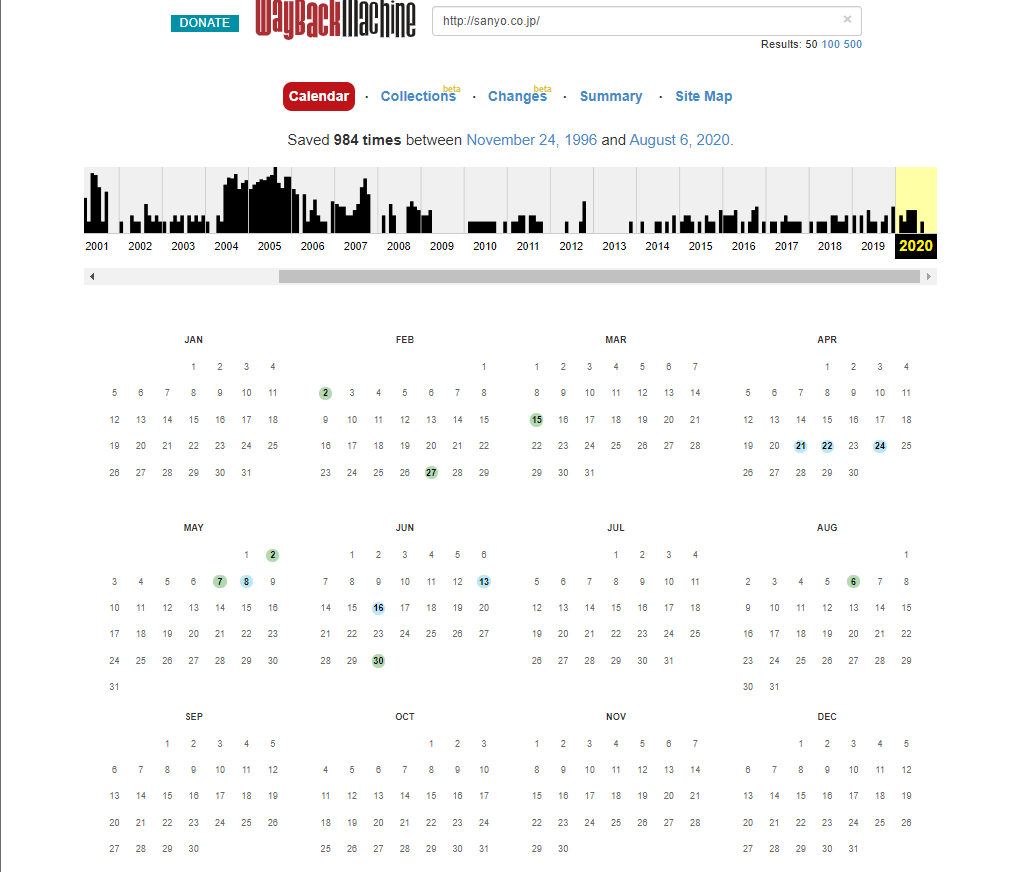
カレンダー上に色がついている日付はデータが収集された日になります。
色分けされているのはそれぞれに意味があり、青は、クローラが関連するキャプチャのために取得したWebサーバーの結果コードが良好であることを意味します。
緑は、クローラがステータスコード(リダイレクト)を得たことを意味します。
オレンジは、クローラーがステータスコード(クライアントエラー)を得たことを意味し、赤はクローラーが(サーバーエラー)を得たことを意味します。
そのため、確認する際は青の日付を選択します。
例では2020年は情報がほぼ取得されていないため、Panasonicに買収された2009年以前で最も更新頻度の高い2005年のページを確認してみます。
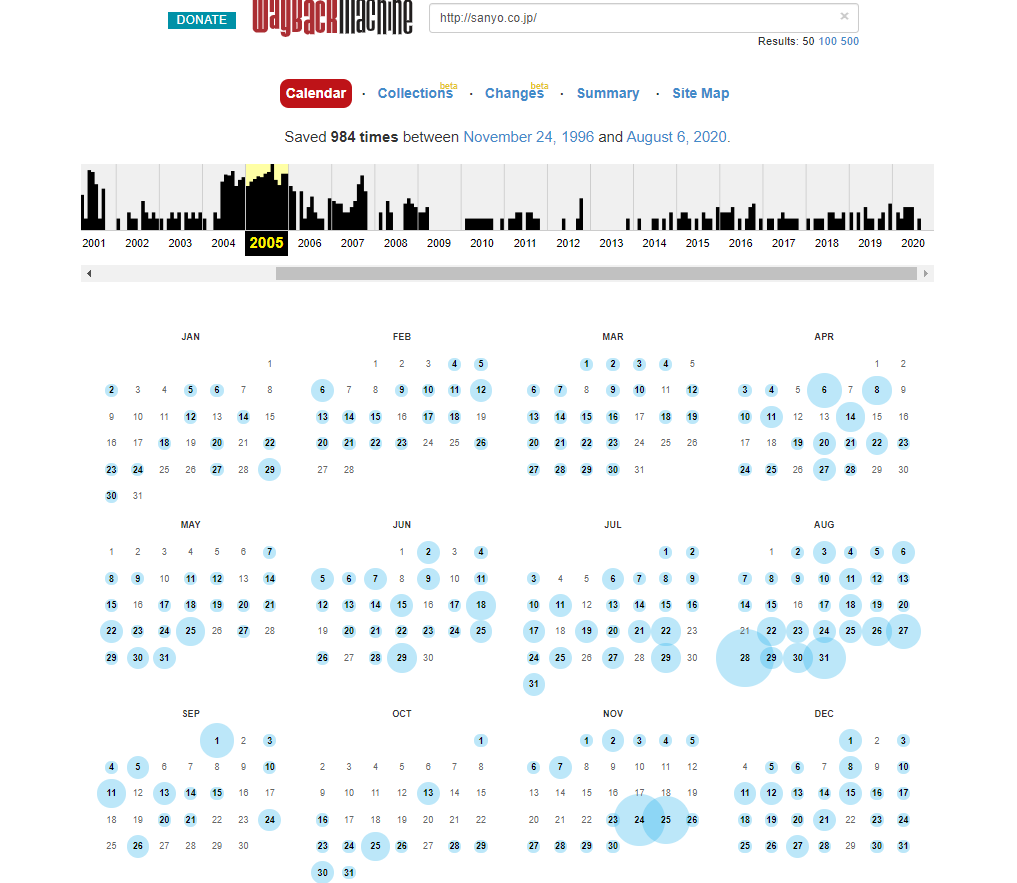
丸の大きさは取得された頻度を示しています。回数が多いと丸が大きく表示されます。
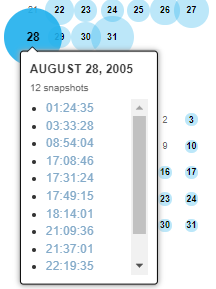
表示されている数字はクローラが取得した時間を示しており、この時間をクリックすると取得した時間の画面を表示することが可能です。
URLが分からないときはどうするか。
昔見たんだけど、お気に入りには登録していないからURLが分からないという場合もあると思います。
その場合は、Advanced Searchで確認できる可能性があります。
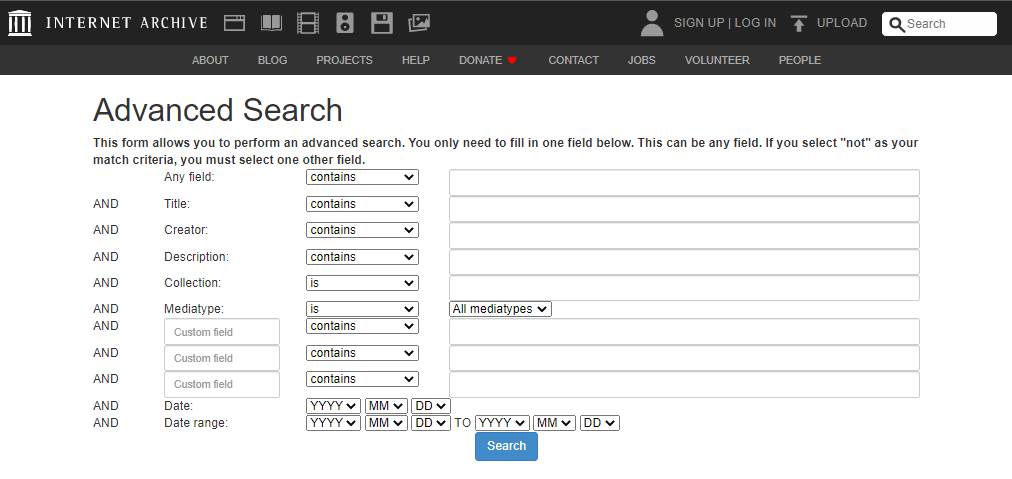
入力項目は以下の様になっています。
真ん中の選択項目はcontains(含む)か、does not contain(含まない)かを選択します。
| 入力項目 | 入力概要 |
| Any field | 自由入力 |
| Creator | サイト作者名を入力 |
| Description | サイトの説明を入力 |
| Collection | コレクションを入力 (インターネットアーカイブ上でアーカイブされたデータはコレクションとして編成されており、 テキストコレクションやオーディオコレクション等のコレクションが存在します。) |
| Mediatype | メディアの種別を入力 (テキストか画像か音声か動画か等) |
| Date | 確認したい日付を入力 |
| Date range | 確認したい日付を年月日単位の範囲で指定して入力 |
検索例で三洋電機を使用したので、こちらでも三洋電機で確認します。
Any fieldに三洋電機を入力してSearchをクリックします。
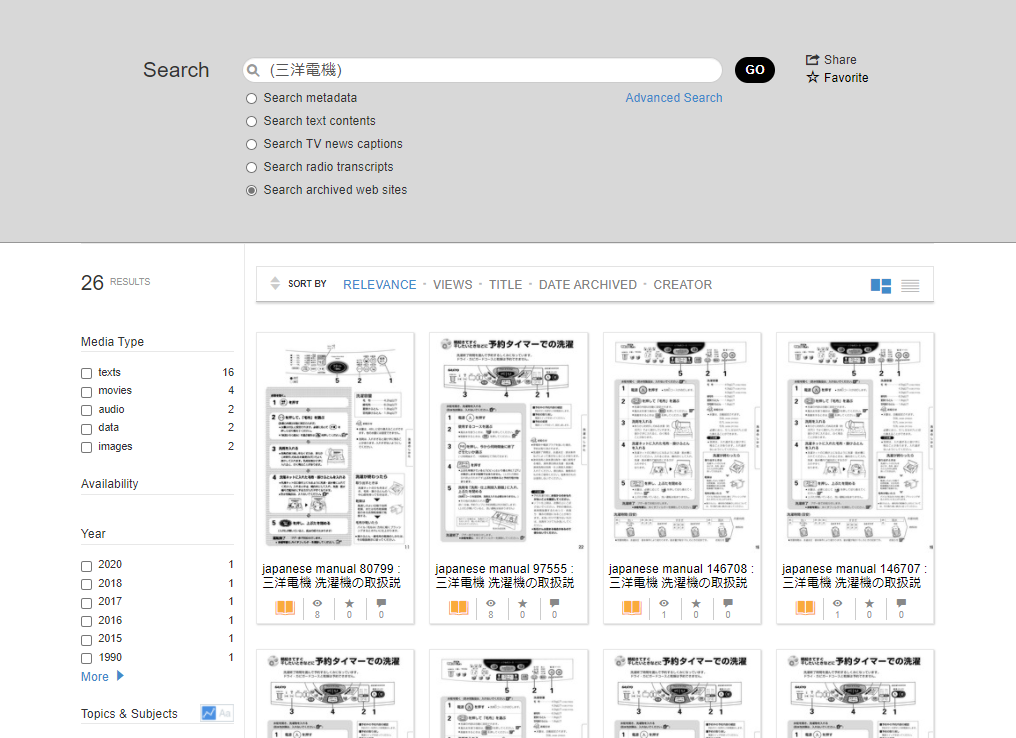
家電のマニュアルや、以前のCM等がヒットしました。
終わりに
以上、Internet Archiveを使用した以前消えてしまったWebサイトを再度確認する方法でした。
消えてしまったデータをアーカイブからサルベージすることもできると思いますので、覚えておいて損は無いかと思います。
また、自動的にデータが取得されているので、取得されては困る場合もあるかと思います。
そういった際はrobots.txtにクローラがデータを取得しないように記載しておけば取得はされないようです。
既に取得されてしまったデータは申請により削除可能なようです。


コメント